인공지능(AI, Artificial Intelligence)이 인간의 학습능력, 추론능력, 지각능력, 자연언어의 이해 능력 등을 인공적으로 구현한 기술이라면 알고리즘(Algorithm)은 입력된 데이터를 일정한 연산과 규칙에 따라 재배열해 AI가 문제를 해결할 수 있게 해주는 논리적 절차를 말한다. 인공지능과 알고리즘은 불가분의 관계이고, 이런 AI 알고리즘을 뒷받침해주는 게 데이터인 것이다. .
AI 얼굴인식은 논란이 끊이지 않는 기술이다. 출입 관리, 신원 확인, 보안 강화 등 그 활용 범위가 무궁무진하지만 사생활 침해, 감시 사회 같은 위험이 상존한다. 보다 근본적인 문제는 이 기술이 100% 신뢰성을 담보할 수 없다는 데 있다. 미국에서는 엉뚱한 인물을 범죄자로 지목해 생사람 잡는 사례가 몇차례 있었다. 100개 이상의 얼굴인식 알고리즘을 조사했더니 흑인과 아시아인들의 얼굴을 제대로 인식하지 못했다는 보도가 나오기도 했다.
이런 논란은 얼굴인식 알고리즘을 생성하기 위한 데이터가 충분히 반영되지 못한데다 유색 인종에 대한 미국 사회의 뿌리깊은 차별 의식까지 답습했기 때문이다. AI 알고리즘이 제대로 작동하기 위해서는 무엇보다 오염되지 않고 편견이 없는 풍부한 데이터가 전제되어야만 한다.
데이터를 얻는 것은 시간이 걸리고 많은 비용을 수반한다. 미국 의회에 난입한 트럼프 지지 시위대의 신원 파악에 동원된 얼굴인식 기술 ‘클리어뷰AI’는 30억장의 사진 데이터를 보유한 것으로 알려졌는데 운전면허 사진 뿐 아니라 소셜 미디어 등에서 수집했다는 의혹이 일었다. 개인 정보 습득 기준은 갈수록 엄격해지고 규제도 심하다. 알고리즘을 형성할 데이터를 대량으로 수집하는 게 그만큼 힘들어졌다.
AI 알고리즘의 적용 범위가 전방위로 확대되면서 이를 생성할 데이터의 수요가 급증하고 있다. 이런 과정에서 데이터를 공급해주는 회사들이 생겨났다. 이스라엘 텔아비브를 기반으로 한 데이터젠(DATAGEN)도 그 가운데 하나다. 데이터젠은 고차원적이고 매우 사실적인 차세대 합성 데이터를 공급해 신속하고 저렴한 비용으로 알고리즘을 개발하고 훈련시킬 수 있다고 홍보한다.
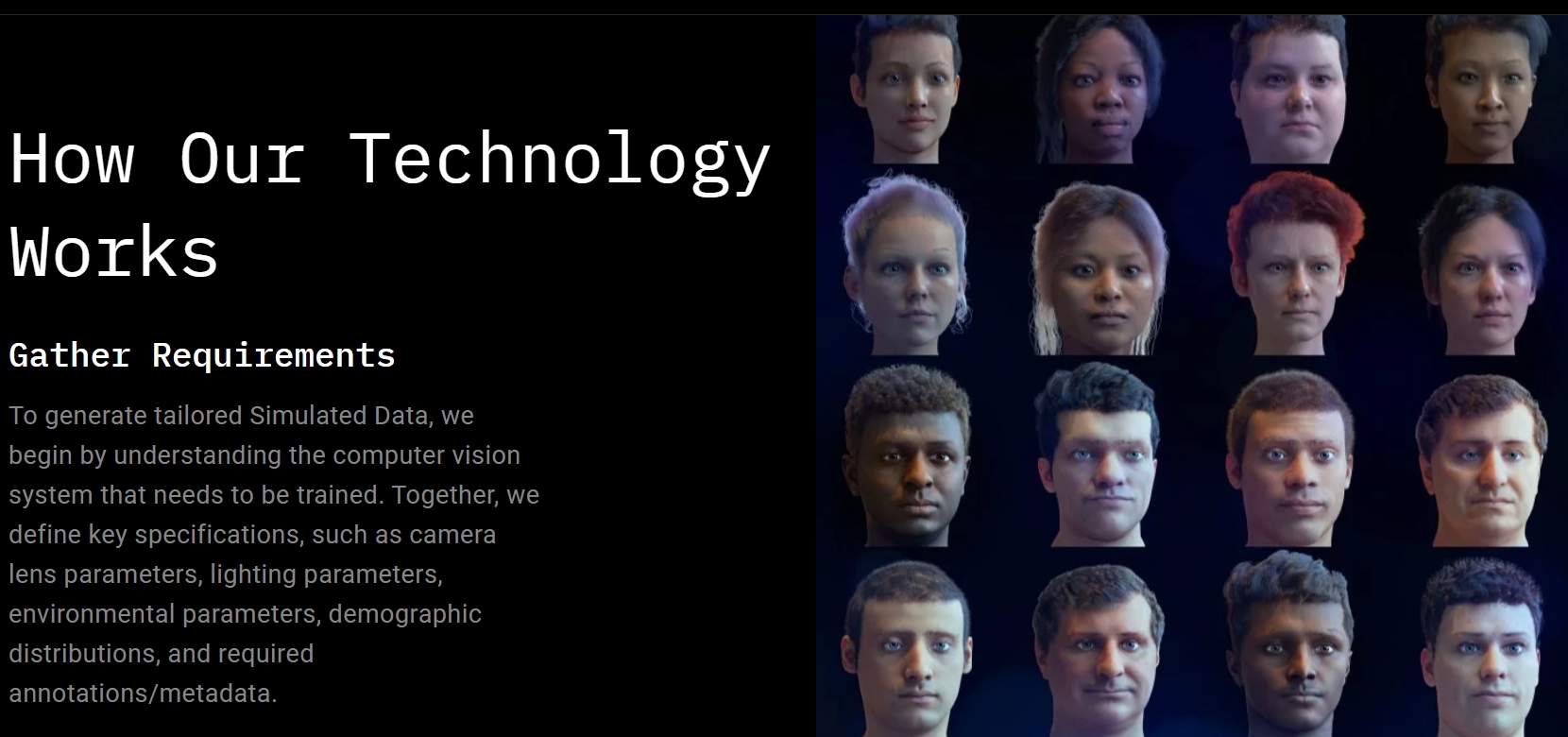 데이터젠 홈페이지 캡처
데이터젠 홈페이지 캡처
합성 데이터는 얼굴, 피부와 질감, 눈의 홍채, 손가락의 굴절 등 실제 인간의 전신을 스캔한 뒤에 이것을 기반으로 인체 각 부분을 3D를 활용해 다양한 형태로 표현해낸다. 이런 방식으로 수많은 가짜 인간, 가짜 얼굴을 만들어 AI 알고리즘 형성을 위한 데이터로 활용하는 것이다. 데이터젠은 미국의 거대 기술 기업 4곳과 이미 협력하고 있다고 밝혔다.
실제 인간 데이터가 아닌 이런 합성 데이터를 활용하면 연령이나 성별, 나이, 인종에 구애 받지 않게 될뿐더러 개인 정보 수집 논란을 피해 원하는 만큼 데이터를 확보할 수 있다. 그래서 누구에게나 적용할 수 있는 범용 얼굴인식 알고리즘을 생성할 수 있게 된다는 것이다. 물론 특정한 목적의 알고리즘을 위한 데이터를 만들어낼 수도 있다.
데이터젠과 경쟁하고 있는 미국 샌프란시스코의 신서시스AI(Synthesis AI)는 최근 4만개의 고해상도 3D 얼굴 모델을 출시했다고 밝혔다. 각 이미지는 얼굴 표정과 머리 모양, 머리카락, 피부 표면의 질감 등에 따라 거의 무한대로 합성 인물 데이터를 창출해 낼 수 있다고 강조한다. 이런 합성 데이터는 스마트카, 무인 상점, 가상현실과 증강현실, 로봇의 활용을 위한 AI 알고리즘으로 뒷받침하게 된다.
 신서시스AI 홈페이지 캡처
신서시스AI 홈페이지 캡처
이런 합성 데이터 회사가 이미 수십 개에 이르는 것으로 확인되고 있다. 금융과 보험, 의료 등 다양한 분야로 합성 데이터의 활용 범위가 계속 확대되고 있다. 그렇다면 합성 데이터는 AI 알고리즘 형성 과정에서의 제기되는 모든 문제를 해결할 만능 열쇠가 될 수 있을까? MIT 테크놀로지 리뷰는 전문가들의 말을 인용해 그 유용성을 인정하면서도 경계를 게을리해서는 안된다고 조언한다.
펜실베니아대 컴퓨터 정보과학 교수인 아론 로스(Aaron Roth)는 합성 데이터가 실제 데이터와 직접적으로 일치하지 않는다고 해서 민감한 개인 정보와 무관하다는 보장은 없다고 말한다. 데이터 과학자이자 알고리즘 감시기관인 ORCAA의 창립자인 합성오닐(Cathy O’Neil)은 합성 데이터가 AI 시스템의 편향을 효과적으로 완화할 수 있다는 증거는 거의 없다고 주장한다. 노스이스턴대 컴퓨터과학 조교수 크리스토 윌슨(Christo Wilson)도 완벽한 합성 데이터가 공정성을 자동으로 보장해주지 않는다고 강조한다. 합성 데이터는 AI 알고리즘에 획기적인 기여를 할 수 있지만 모든 기술이 다 그렇듯 지나친 낙관은 금물이고, 끊임없이 보완이 필요하다는 것이다.

























합성데이터는 생소하네요. 어디선가 들었어도 무의식에도 남지 않았을지도요^^;
아직 아는 바가 없어 합성 데이터가 실제 데이터보다 나은지 아닌지도 감은 안 오구요.
일단 실제 데이터와 직접적으로 일치하지 않을 수 있다는 건 공감이 가네요.
또한 AI 시스템의 편향을 효과적으로 완화할 수 있다는 증거는…
데이터가 실제가 아닐뿐 그 정보가 편향적이지 않을 수 있는지는 데이터를 제공하는 회사나 사람에게 달려있지 않을까 생각이 드네요.
편견과 편향에서 자유로운 인간이 있을 수는 없지 않을까 싶어서요. 자라온 환경과 문화가 일단 굴레가 될 수 밖에 없을테니까요.
어쨌든 직접적 정보 노출이 없고 편향된 알고리즘의 수정을 위해 노력한다니, 문제해결을 위한 인간의 노력이 있다는게 좋네요^^
합성된 데이터…에공 넘쳐나는 데이터에 또 합성까지 해서공급도 해주는 회사라~
데이터를 위한 또다른 데이터…복제양 돌리?
그렇다고 편향과 편견이 사라지진 않을터
거듭나고 확장되는 엔트로피의 증가
정말 미래를 예상한다는 건 저는 불가항력입니다