원문 보기: A Scalable Approach to Reducing Gender Bias in Google Translate
언어 번역 기계학습(Machine learning) 모델은 학습 과정에서 각종 사회적 편향이 반영되어 왜곡될 수 있다. 그러한 사례 중의 하나인 성 편견은 한쪽 성에 국한되는(gender-specific) 구절과 그렇지 않은 구절을 해석할 때 명확해진다. 예를 들어, 구글 번역기는 오래전부터 터키어를 번역할 때 “He/She is a doctor”를 남성형으로, “He/She is a nurse”를 여성형으로 인식해왔다.
불공평한 편향이 새롭게 생기거나 더 강해지는 상황을 피하기 위해 노력하는 구글의 AI 원칙에 따라, 우리는 2018년 12월에 한쪽 성에 국한된 번역 서비스를 제공했다. 이는 사용자의 질문 구절이 성 중립적인(gender-neutral) 경우, 구글 번역기가 여성형, 남성형 모두를 고려한 번역 옵션을 보여주는 것이다. 이 작업을 위해, 우리는 3단계의 접근 방식을 고안했는데, 성중립적인 질문 구절 탐지, 한쪽 성에 국한된 번역 생성, 그리고 정확도 확인이 그것이다.
우리는 이 접근 방식을 사용하여 먼저 (터키어->영어) 번역에서 한쪽 성에 국한된 번역을 이루어냈고, 현재는 구글 번역기에서 가장 인기가 많은 (영어->스페인어) 번역도 제공하고 있다.
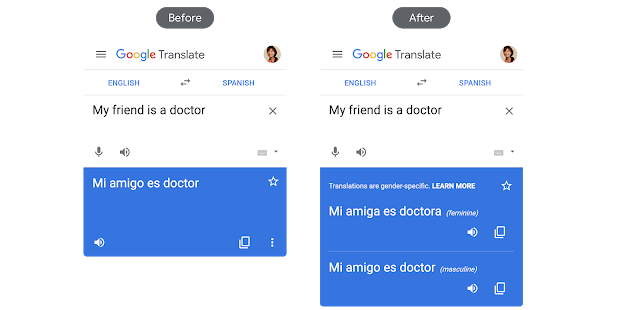
왼쪽: 성 중립적인 영어 구절을 한쪽 성에 국한된 스페인어로 번역한 기존 사례, 이 경우 편향된 결과만이 주어진다. / 오른쪽: 새로운 번역기가 제공한 여성형, 남성형 번역 옵션
하지만 이런 접근 방식이 더 많은 언어에 적용되면서 확장 가능성에 대한 이슈가 생겼다. 먼저, 신경망 기계번역(neural machine translation, NMT)을 사용하여 남성형, 여성형 번역을 독립적으로 생성하다 보니 재현율(recall)이 낮았다. 또한, 번역 질문의 40%가량은 한쪽 성에 국한된 번역을 제대로 제공하지 못했다.(두 가지 번역이 완벽히 동일한 경우를 기준으로 계산했다) 마지막으로 모든 구절의 성 중립성을 탐지하는 분류기를 설계하는 것은 엄청난 데이터를 필요로 한다.
이번 글에선 새로운 한쪽 성에 국한된 (영어->스페인어) 번역을 출시함에 따라 기존과는 다른 패러다임을 사용한 업그레이드 버전의 접근 방식을 소개하려고 한다. 이 패러다임은 초기 번역을 다시 작성하거나 편집하여 성 편견을 해결하는 것이다. 우리의 접근 방식은 특히 성 중립적인 구절을 영어로 번역할 때 더욱 확장 가능한데, 이는 중립성 탐지를 더 이상 필요로 하지 않기 때문이다. 이를 기반으로 한쪽 성에 국한된 번역 서비스를 확장하여 (핀란드어, 헝가리어, 페르시아어->영어) 번역이 가능해졌다. 기존의 (터키어->영어) 번역 시스템 또한 새로운 재작성 기반(rewriting-based) 방법으로 대체했다.
재작성 기반 한쪽 성에 국한된 번역
재작성 기반 방법의 첫 단계는 초기 번역을 생성하는 것이다. 이후 성 중립적인 구절에 대해 한쪽 성에 국한된 번역이 이루어졌는지 확인 작업을 거친다. 만약 그렇다면 문장 단위의 재작성 시스템을 적용하여 초기 번역에 반대되는 성별을 반영한 대체 번역을 생성한다. 마지막으로 초기 번역과 재 작성된 번역 간의 차이점은 오직 성별만 될 수 있도록 재차 검토한다.

위: 기존 접근 방식 / 아래: 재작성 기반 접근 방식
재작성 모델
재작성 모델 설계는 남성형과 여성형 번역을 모두 포함한 구절 쌍으로 이루어진 수백만 개의 훈련 데이터를 생성하는 것이 중요하다. 이러한 데이터는 바로 얻어서 이용할 수 있는 상황이 아니기 때문에 우리는 새로운 데이터셋을 생성했다. 대규모 단일 언어 데이터셋부터 시작하여 성별과 관련된 대명사에 대해 남성형은 여성형으로, 여성형은 남성형으로 재 작성된 번역본 후보를 프로그래밍을 통해 생성했다. 여성형 대명사 “her”을 “him” 또는 “his”로 맵핑(mapping)하거나 남성형 대명사 “his”를 “her” 또는 “hers”로 맵핑하는 것과 같이 여러 개의 유효한 후보가 있을 수 있기 때문에 문맥에 따라 정확한 것을 선택할 메커니즘이 필요했다. 이를 해결하기 위한 후보로는 구문 파서(syntactic parser)와 언어 모델(language model)이 있었다. 구문 파서 모델은 각 언어마다 라벨링된 데이터셋 훈련이 필요하기 때문에 비지도 학습이 가능한 언어 모델보다 확장성이 낮다. 따라서 우리는 수백만 개의 영어 문장으로 훈련된 내부 언어 모델을 선택했다.
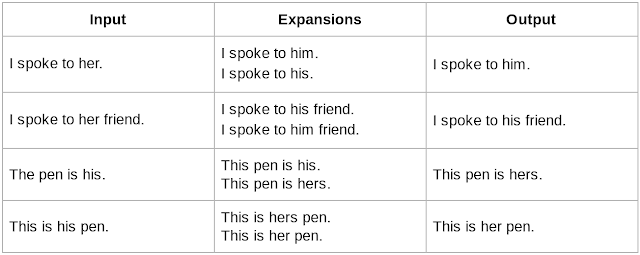
이 표는 데이터 생성 과정을 보여준다. 입력(input)부터 시작해서 번역 후보를 생성하고 내부 언어 모델을 통해 정확한 문장을 출력(output)한다.
위 데이터 생성 과정은 남성형 문장 입력을 여성형 문장 출력으로, 여성형 문장 입력을 남성형 문장 출력으로 만드는 훈련 데이터를 보여준다. 우리는 이런 데이터를 병합하여(merge) 단층 트랜스포머 기반(transformer-based)의 시퀀스-투-시퀀스(sequence-to-sequence, 번역, 챗봇 구현에서 가장 활발히 사용되고 있는 RNN 기반의 언어 모델) 모델을 적용했다. 또한, 모델의 견고성을 높이기 위해 훈련 데이터에 구두점 및 대소문자 변형을 도입했다. 우리의 최종 모델은 99%의 정확도로 남성형, 여성형으로 재작성된 번역본을 생성할 수 있었다.
평가
우리는 편향 감소라는 새로운 평가 방법을 고안했다. 이는 기존 번역 시스템과 새로운 시스템을 비교하여 편향의 상대적인 감소 정도를 측정한다. 여기서 말하는 “편향”은 한쪽 성에 치우치지 않은 구절을 번역할 때 특정성별을 선택한 것으로 정의된다. 예를 들어, 현재 시스템이 90% 편향되었고 새로운 시스템은 45% 편향되었다면 상대적으로 50% 정도의 편향 감소가 일어난 것이다. 이런 측정법을 사용하여 우리는 (헝가리어, 핀란드어, 페르시아어->영어) 번역에서 90% 이상의 편향 감소를 이루어냈다. (터키어->영어) 번역 시스템의 편향 감소 정도는 기존 60%에서 95%로 증가했다. 결론적으로 우리 시스템은 평균 97%의 정밀도(precision)로 한쪽 성에 국한된 번역을 실행할 수 있게 되었다.
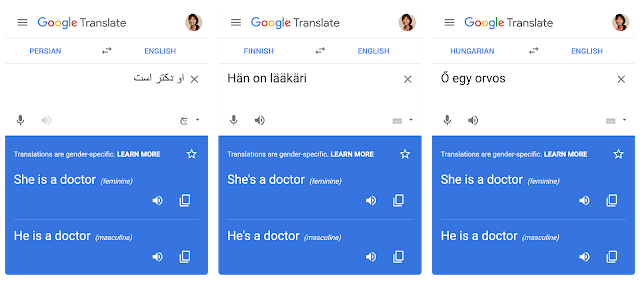
우리는 한쪽 성에 국한된 번역의 품질을 높이는 동시에 지원 언어를 4개 더 늘림으로써 큰 발전을 이루어냈다. 앞으로 우리는 구글 번역기에 존재하는 성 편견을 해결하고 문서 단위의 번역에도 적용 가능하도록 노력할 것이다.


























음….구글 번역이 덜 편향적인 관점으로 번역을 해주며 그 번역언어종류도 늘어난다는 거지요? ㅎㅎ
네 맞습니다. 다만, 덜 편항적인 번역 서비스를 제공하는 방향이 어떨 때는 She is a doctor, 어떨 때는 He is a doctor로 출력하는 것이 아니라 둘 다 모두 제공하는 것이죠^^ 특히, 스페인어의 경우 명사, 동사에도 남성형, 여성형이 구분되어 있어 이번 번역 서비스의 좋은 실험 모델인 것 같네요.